

こんにちは。テンダのAI推進委員会のメンバーKです。
今回はAmazon Rekognition カスタムラベルについて調べ、実際に検証を行ってみました。

目次
もくじ
Amazon Rekognition カスタムラベルとは
Amazon Rekognition カスタムラベルはAWSが提供する画像の分析サービスです。
画像の中にあるオブジェクトやシーン、概念を検出可能です。
元々Amazon Rekognitionというサービスはあったのですが、学習済みモデルしか利用できないため独自に検出対象を設定することはできませんでした。
カスタムラベルに対応したことで独自にオブジェクトやシーン、概念を検出するモデルを作成することができるようになりました。
これにより自社のビジネスに合わせた画像の物体やシーン検出に活用が可能となったわけです。
たとえば、大量にある写真の中から自社の看板が写ってるものを見つける、自社商品を種類別に分類するといった利用が考えられますね。
〇ォーリーも簡単に見つけられそうです。
現在の利用可能リージョン
以前は一部の海外リージョンでのみ利用可能でしたが、2021年2月現在は東京リージョンでも利用可能となっています。
料金形態について
Amazon Rekognition カスタムラベルはトレーニングと推論の2種類に分かれており、それぞれに料金が発生します。
トレーニング時間
Amazon Rekognition カスタムラベルのカスタムモデルを構築するために、まずは対象を学習するトレーニングが必要です。
料金は1時間単位で発生しますが、学習は複数のコンピューティングリソースで並行して行われる場合もあるため、実際にかかった時間より大きく請求されることもある模様。
トレーニング時間がどれだけかかるか不安ですがAmazonによると下記の通り。
一般論ですが、モデルの 90% のトレーニングは 24 時間未満で終わります。トレーニング時間が 72 時間を超えるモデルは自動的に終了されます。自動終了したトレーニングで請求されることはありません。
東京リージョンでの料金は 4.00USD/時間 です(2021年2月現在)。
推論時間
トレーニングしたカスタムモデルを利用するためにも時間ごとの費用がかかります。
リソースのプロビジョニングを解除しないままだと、処理をしてなくても課金されるので要注意です。
1時間ごとに処理できる画像の枚数は画像のサイズやカスタムモデルの複雑さなどで変わります。
トレーニング同様、コンピューティングリソースで処理する場合もあり実際にかかった時間よりも大きく請求されることがあります。
東京リージョンでの料金は 1.37USD/時間 です(2021年2月現在)。
検証内容
ラーメンが「二郎系ラーメン」か「普通のラーメン」かを判定してみました。
筆者がラーメン好きだからです。それ以上の理由はありません。
なお、諸般の理由によりほとんどの画像にはモザイクをかけています。
画像の用意
最初に判定に使用する画像を用意します。

二郎系ラーメン

普通のラーメン
二郎系のラーメンの画像と普通のラーメンの画像、それぞれ15枚ほど用意しました。
プロジェクトを作成
ここからは実際の操作手順です。
検証当時は東京リージョン未対応だったため、対象リージョンをバージニア北部で行ってます。
リージョンをバージニア北部にして、「カスタムラベルを使用」をクリック。
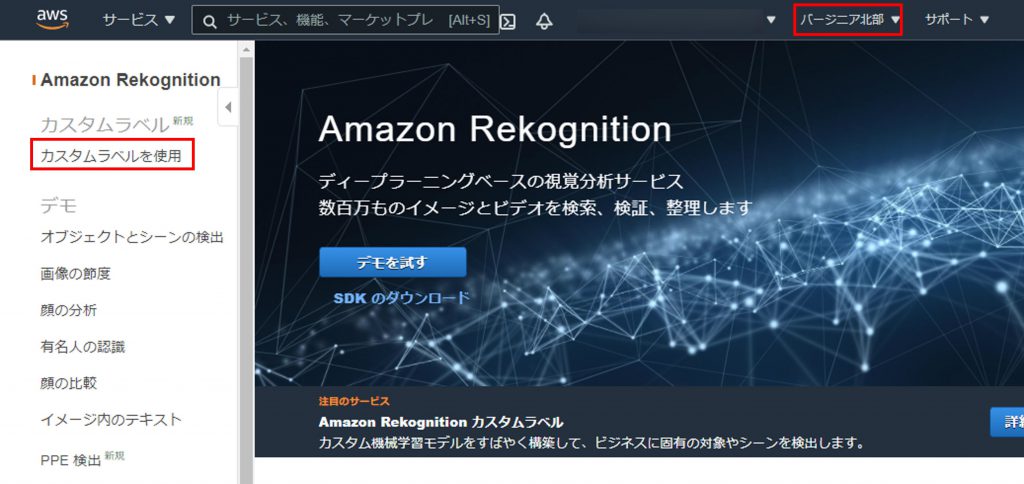
次の画面で、「ご利用開始にあたって」をクリック。
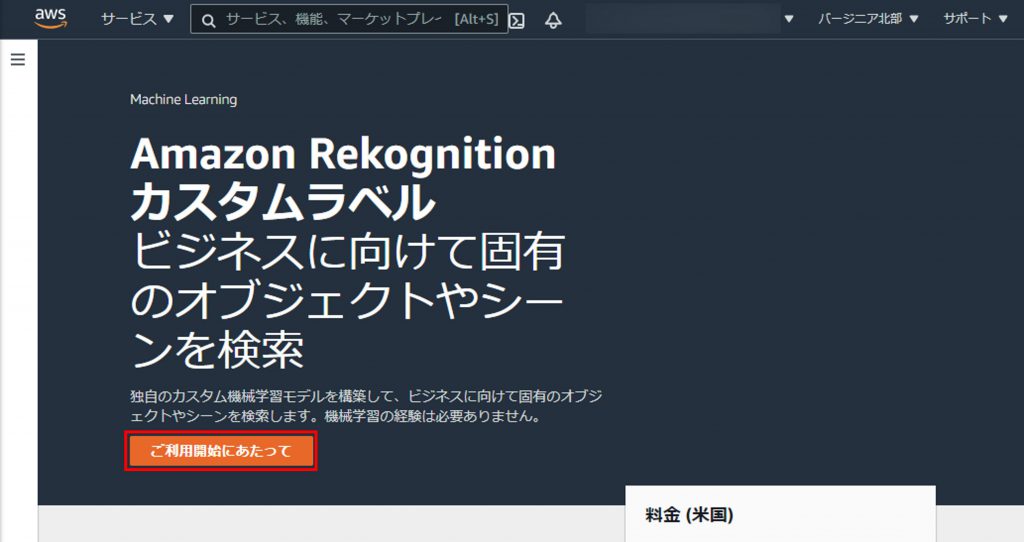
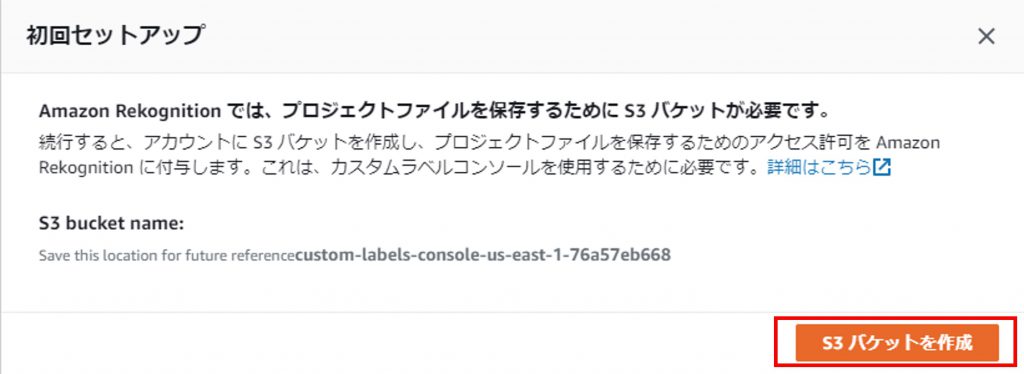
S3のバケット作成を促されるので、「S3バケットを作成」をクリックして、S3のバケットを作成。
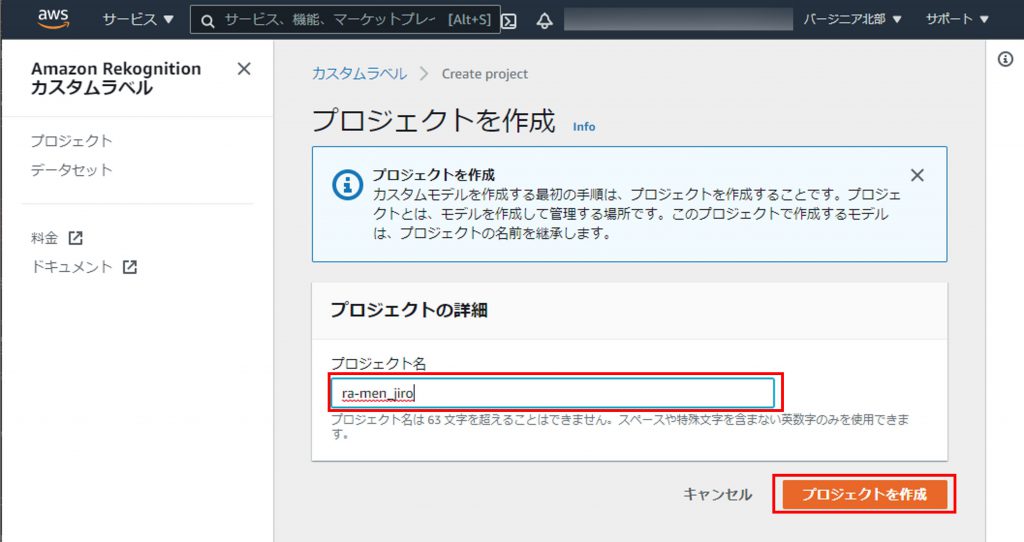
プロジェクト名を入力して、「プロジェクトを作成」をクリック
データセットの作成
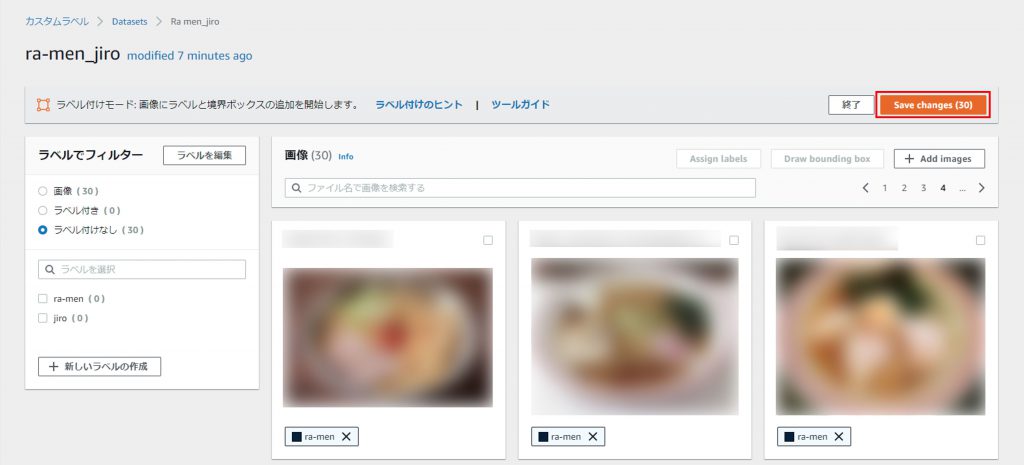
「Create Dataset」をクリックしてデータセットを作成。
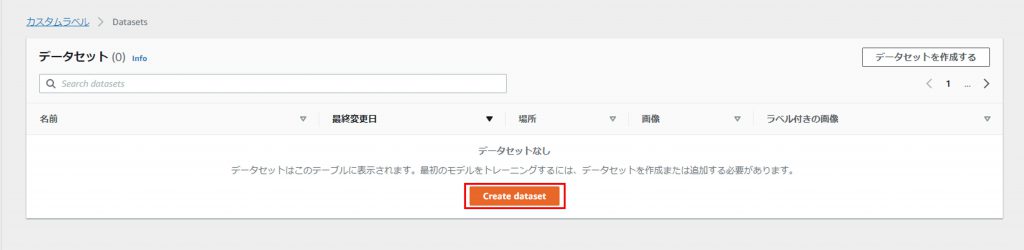
データセット名を入力して、画像の場所を選択し、(今回は「コンピュータから画像をアップロードする」を選択)「提出」をクリック。
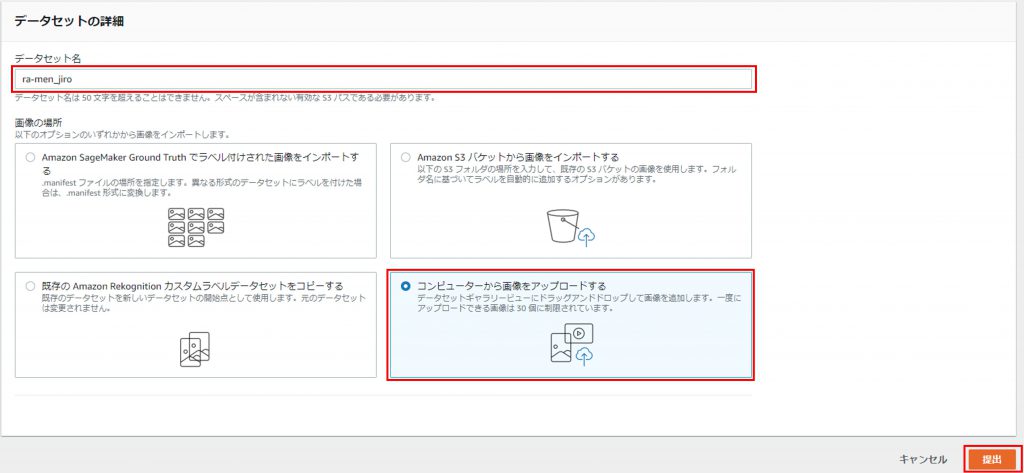
「Add images」をクリックする。
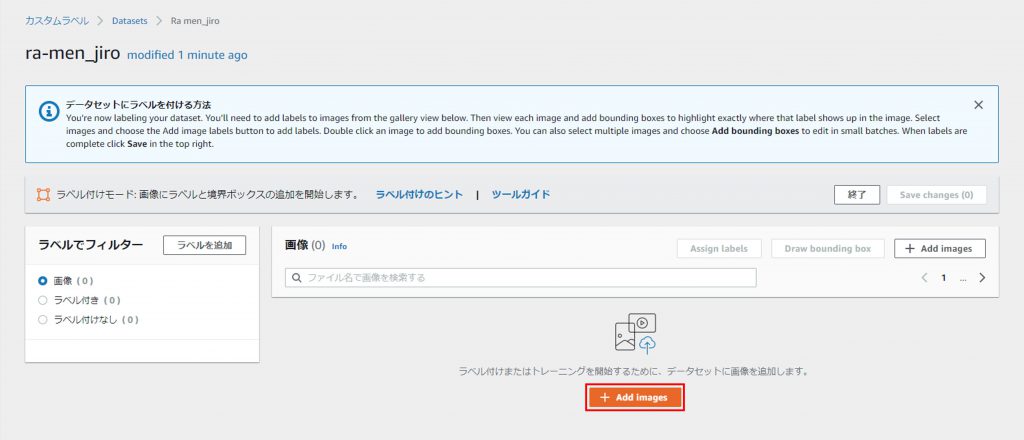
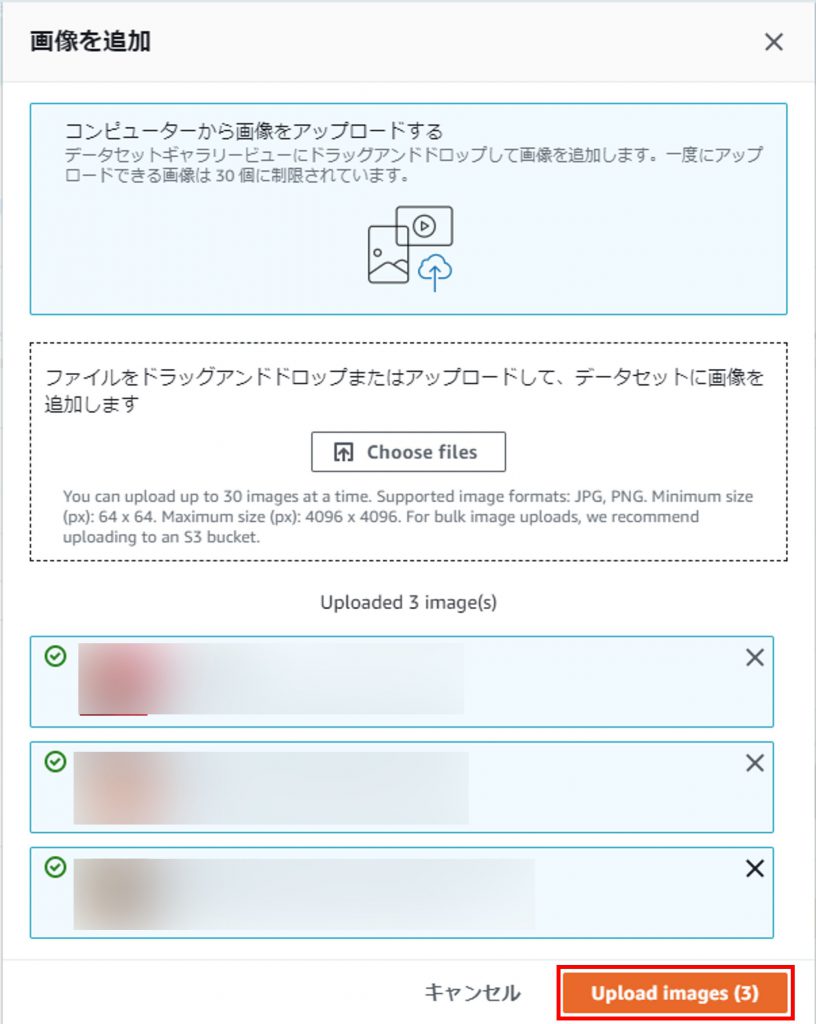
用意した画像をドラック&ドロップでアップロード。
ラベルの作成
アップロードした画像に対し、二郎系のラーメン(jiro)と普通のラーメン(ra-men)のラベルを設定していきます。
「ラベルの追加」をクリック。
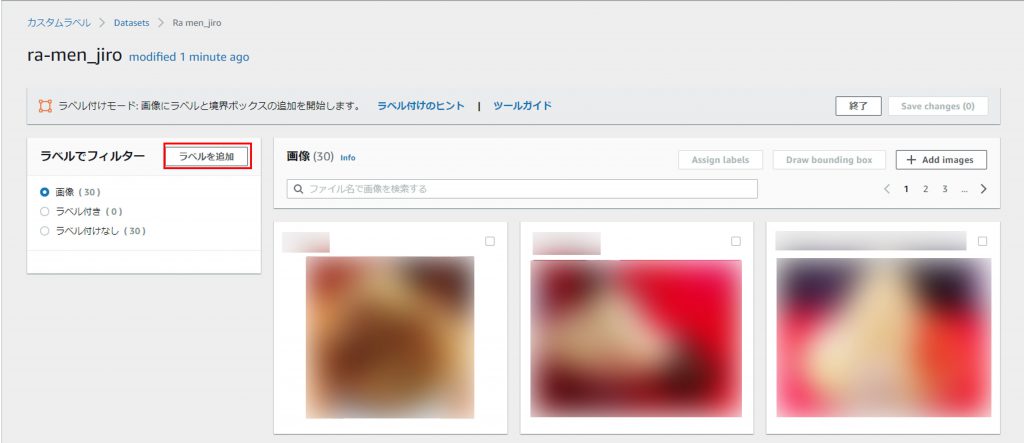
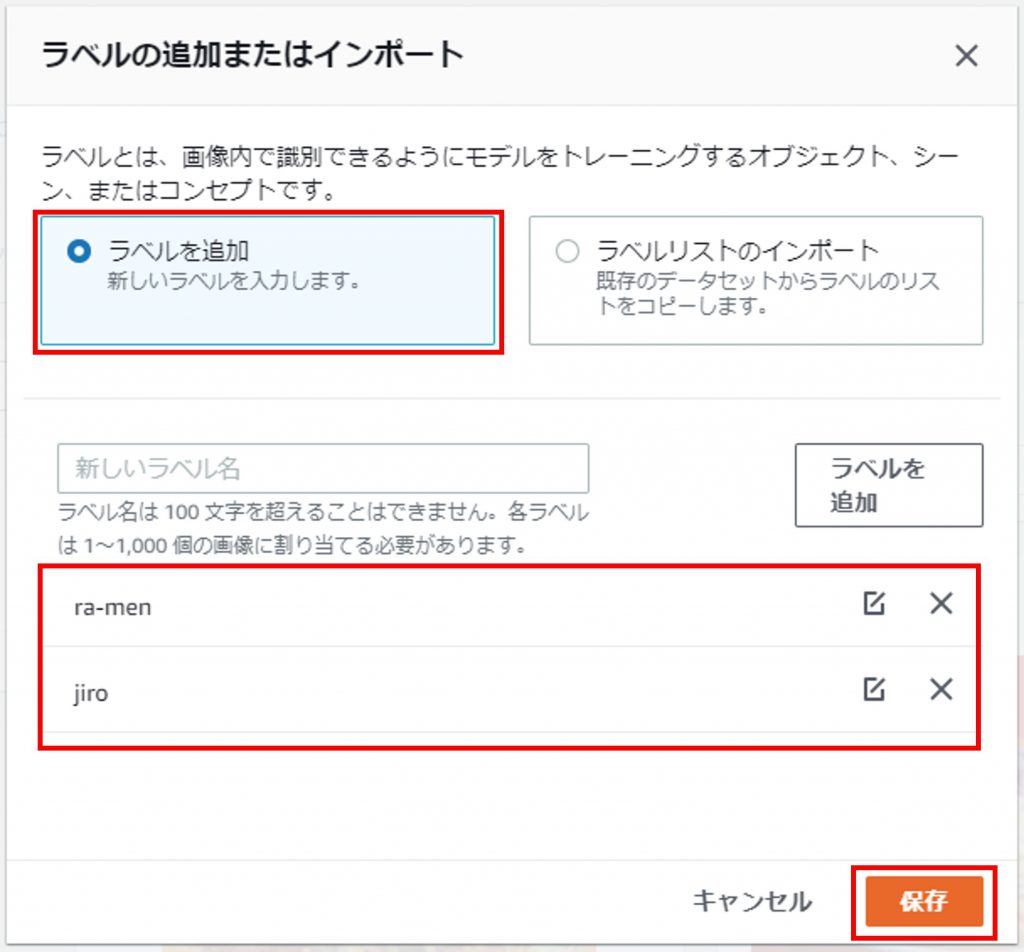
「ラベルを追加」からラベルを追加する。
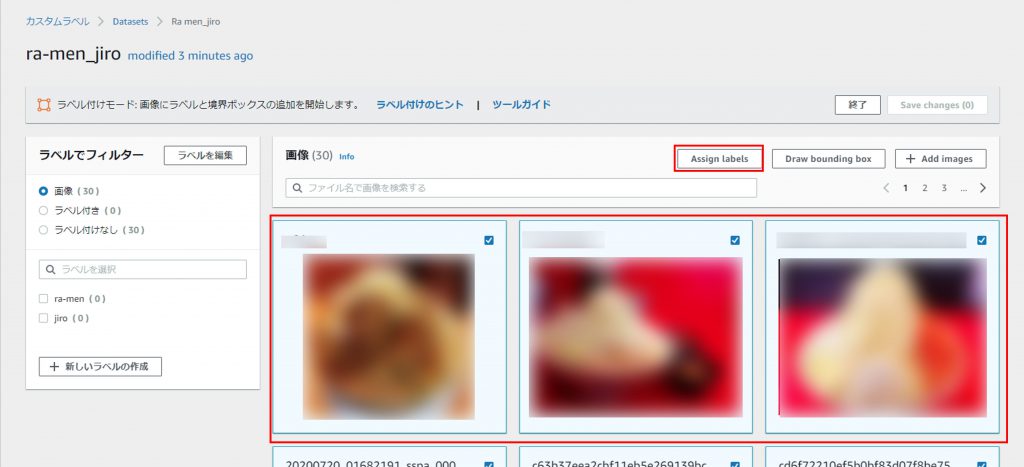
ラベルを画像に割り当てる
ラベル付けしたい画像を選択して、「Assign Labels」をクリック。
選択した画像に付けたいラベルを選択して、「Assing」をクリック。
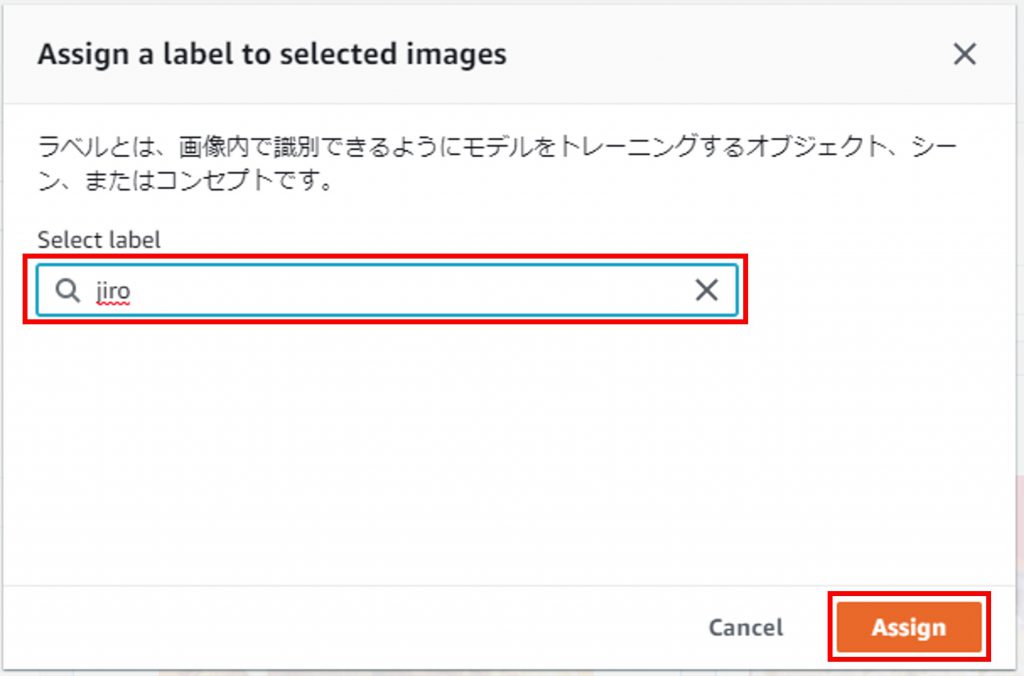
画像の下に選択したラベルが表示される。
もし間違ってラベルを付けた場合はラベル横の「×」をクリックして削除可能。
ラベルを付け終えたら「Save Changes」をクリックして保存。
モデルのトレーニング
ここからが費用が発生するトレーニングの段階です。
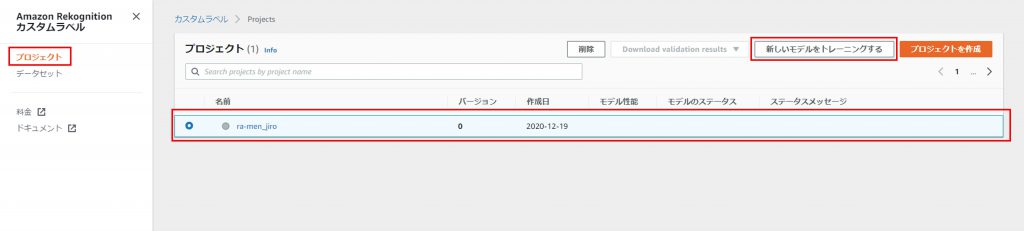
プロジェクトに戻り、先程作成したプロジェクトを選択して、「新しいモデルをトレーニングする」をクリック。
「トレーニングデータセットを選択」で先程作成したデータセットを選び、「テストセットの作成」の欄は「トレーニングデータセットを分割」を選択する。
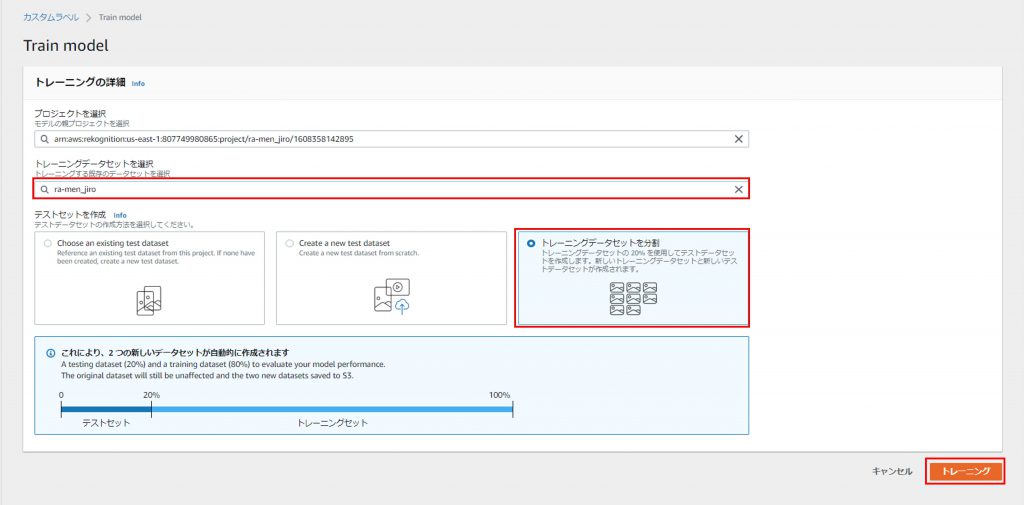
最後にトレーニングをクリック。
しばらく待ってモデルのステータスが「TRAINNG_COMPLETED」になったらトレーニング完了。
今回のモデルのトレーニングには1時間くらいかかりました。
モデルを動かして画像を分析してみる
画像を分析するには対象の画像をS3にアップロードしてある必要があるので、最初にS3の準備をします。

S3の画面へ行き、バケットを作成をクリック
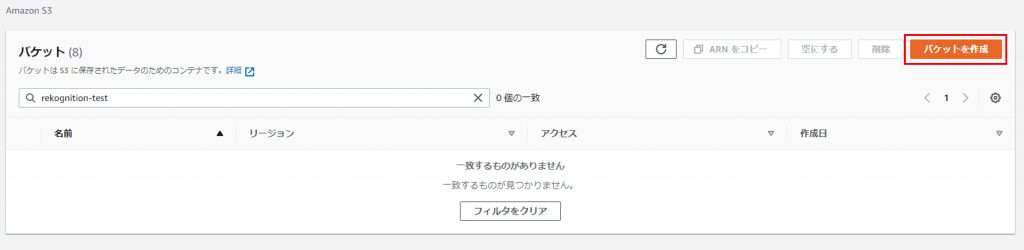
バケット名とリージョンを設定しバケットを作成する。
Amazon Rekognition カスタムラベルのプロジェクトと同じリージョンである必要があるので適宜変更。
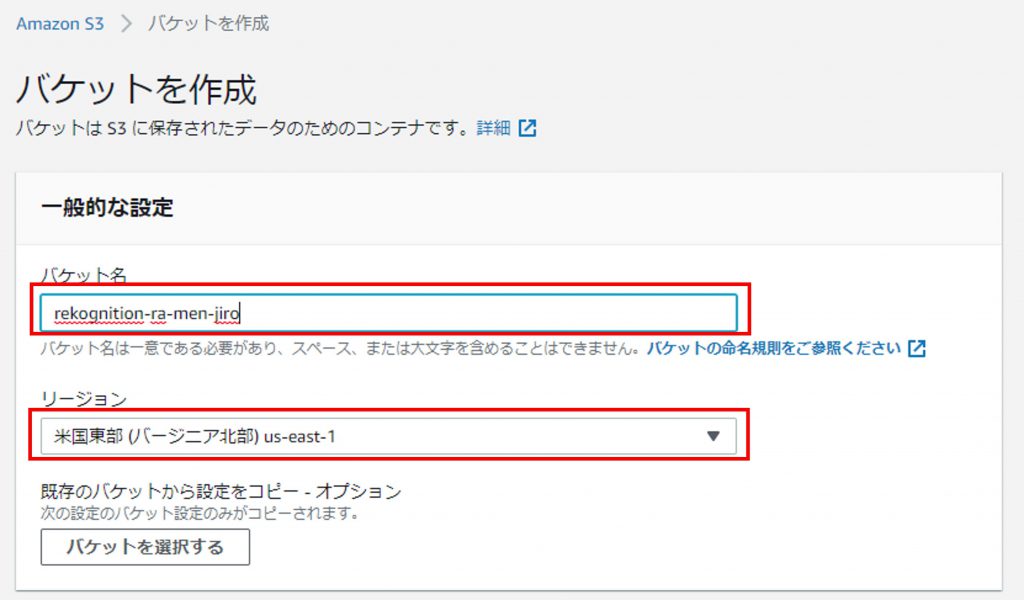
作成したバケットをクリックします。

バケット直下に分析したい画像をアップロードします。
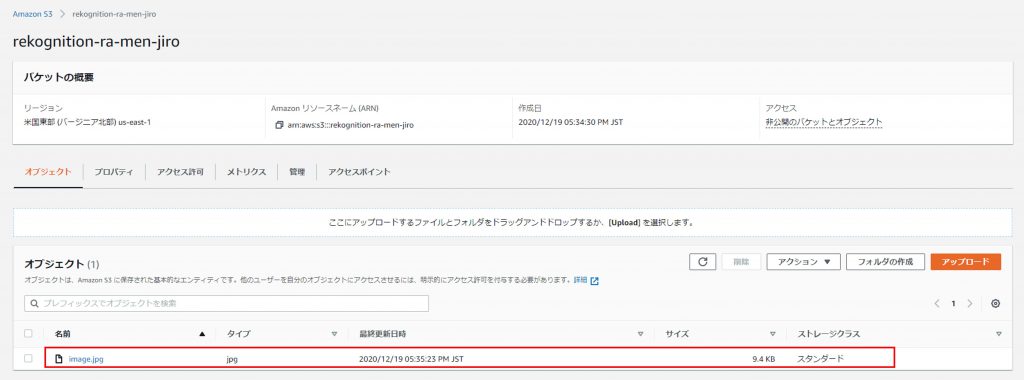
写真ACからダウンロードした二郎系のラーメンをアップしてみます。
(途中の手順は別画像で実行した際のキャプチャを使用しています。権利上の都合でフリー素材に変更しております。)

モデルを開始する
今回作成したトレーニングが完了した状態のモデルをクリック。

「モデルを開始する」ためAWS CLI commandを使用します。
実行にはコマンドプロンプトを利用します。
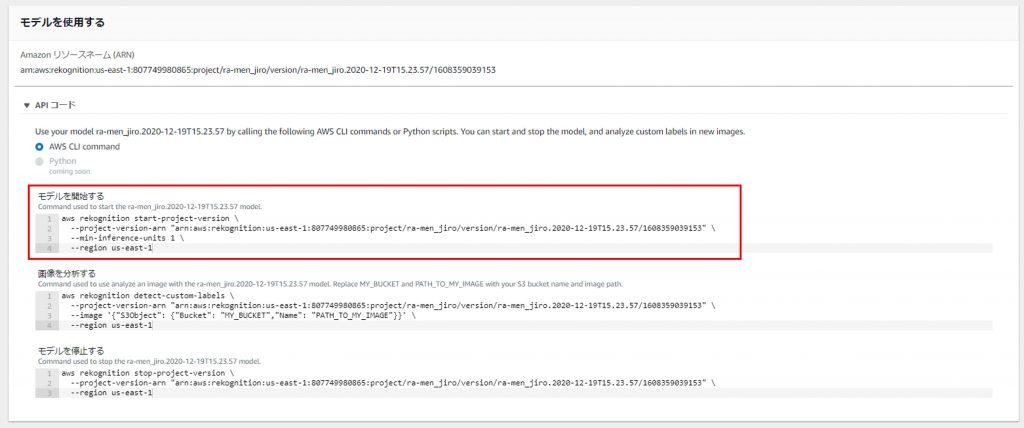
コマンドプロンプトで実行。
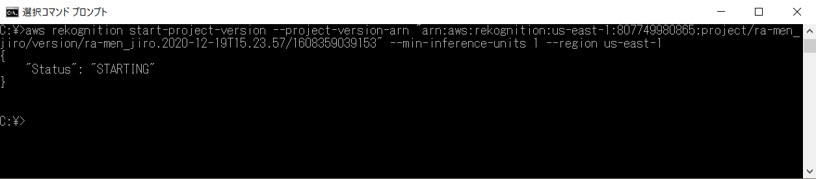
コマンドプロンプトでコマンドを実行すると、モデルのステータスが「STARTING」になります。

しばらく待つと「RUNNING」になるのでそれまで待ちます。30分くらいかかりました。
画像を分析する
画像を分析するAWS CLI commandはこちら。
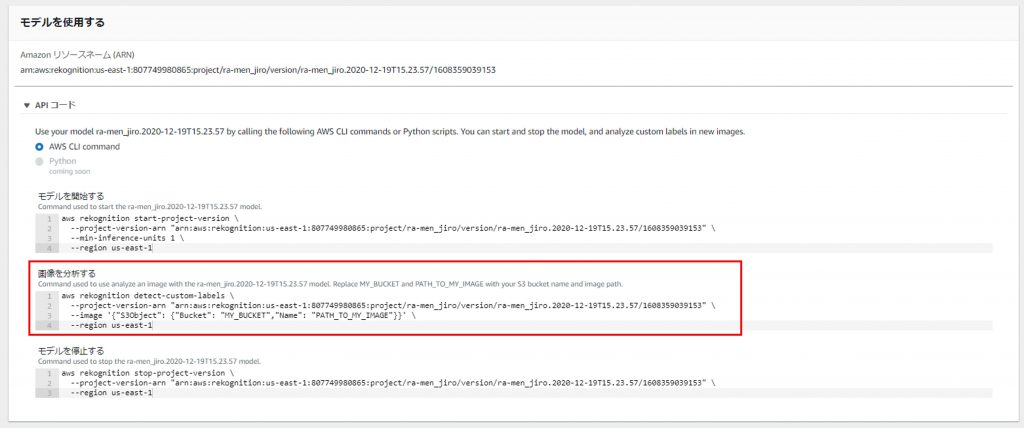
以下の様に書き換えます。
|
1 |
aws rekognition detect-custom-labels --project-version-arn "arn:aws:rekognition:us-east-1:807749980865:project/ra-men_jiro/version/ra-men_jiro.2020-12-19T15.23.57/1608359039153" --image "{\"S3Object\":{\"Bucket\":\"rekognition-ra-men-jiro\",\"Name\":\"image.jpg\"}}" --region us-east-1 |
MY_BUCKETをさきほど分析画像をアップロードしたバケット名、PATH_TO_MY_IMAGEをアップロードした画像名に置き換えています。
(ちなみに、Windowsのコマンドプロンプトで実行する際は「–image “{\”S3Object\”:{\”Bucket\”:\”rekognition-ra-men-jiro\”,\”Name\”:\”image.jpg\”}}”」のように置き換える必要があります)
コマンドプロンプトで実行。
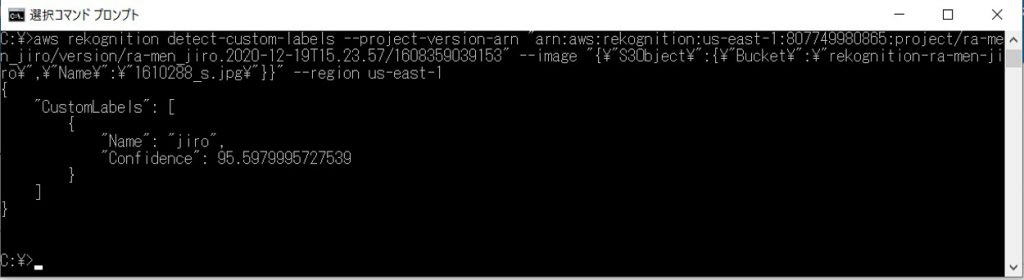
上記キャプチャ内のNameがラベル、Confidenceが信頼度です。
さきほどの画像は95.5%の確率で二郎系ラーメンと判別されたことになります。
期待通りの結果が得られました。
他の実行結果
他の画像も試してみます。

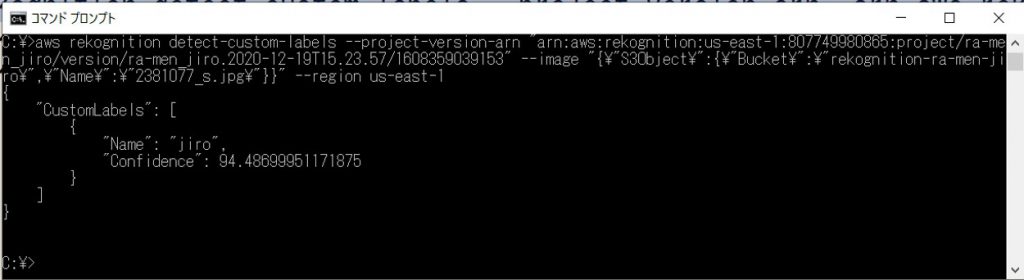
jiro 94.4%。

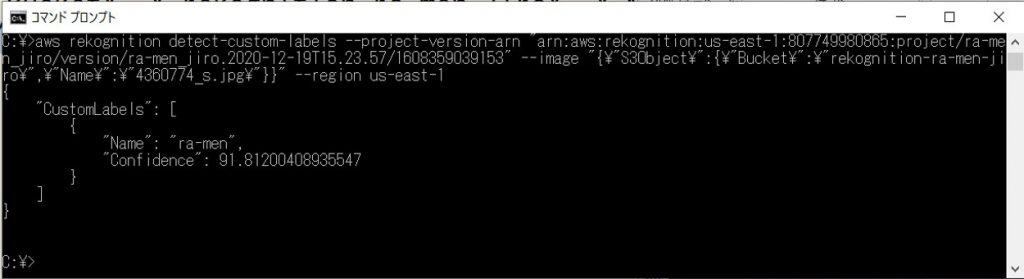
ra-men 91.8%
といった具合にラベル分けも適切にされていることが確認できます。
モデルを停止する
モデルが起動したままだと推論時間が加算され続けるため、不要なときは停止しておきます。
モデルを停止するためのAWS CLI commandを使用します。
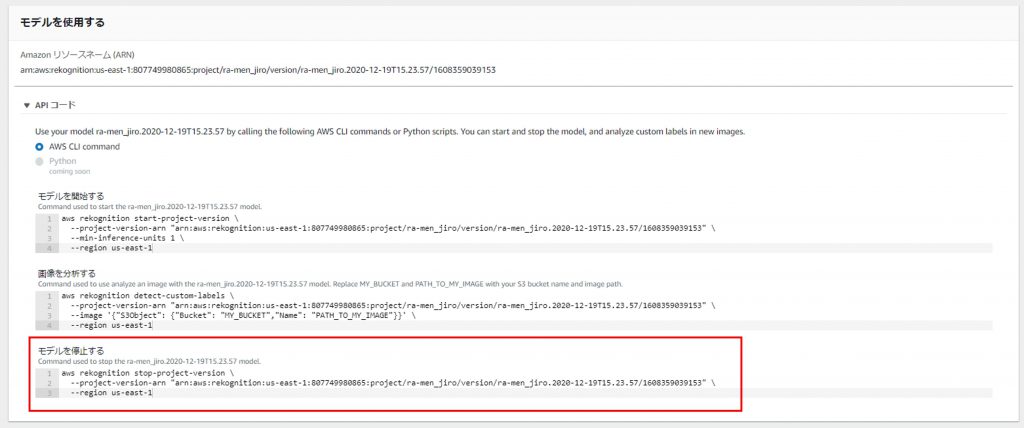
コマンドプロンプトで実行。
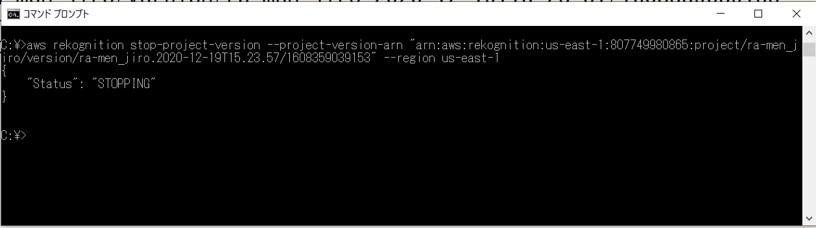
モデルのステータスが「STOPPED」になるとモデルの停止が完了となります。

検証してみての感想
以上がAmazon Rekognition カスタムラベルの検証の流れです。
30枚程の画像でもしっかり判定ができ、その精度の高さに驚きました。
料金は決して安くはないので個人用途では当然躊躇しますし、ビジネス用途でも充分に採算が取れるのか収益性の検討も必要そうです。
せめて、推論時間の料金が安くなれば活用の幅が広がりそうです。
機会があればまた触ってみたいと思います。メンバーKでした。